You just accepted a new case. Retaining counsel sends you a 10 GB document dump — thousands of PDFs spanning engineering specs, test results, patent filings, and internal correspondence. You need to sound intelligent in an interview next week. The clock is ticking. Do you reach for ChatGPT?
If your answer is “yes,” you may be walking into a career-altering trap. In courtrooms across the country, expert witnesses and attorneys are discovering — the hard way — that the AI tools they rely on are not the private workspaces they assumed them to be. But there is a better path, and it’s one that plays directly to the technical strengths you already have.
The Wreckage Is Already Piling Up
The past two years have produced a sobering string of AI-related litigation disasters. Courts are not merely cautioning practitioners — they are sanctioning them, striking their declarations, and destroying their professional credibility.

In Mata v. Avianca, lawyers submitted fabricated citations generated by ChatGPT and were formally sanctioned. In Kohls v. Ellison, an AI safety expert — of all people — had his entire declaration excluded after GPT-generated false citations “shattered his credibility.” And in Concord Music Group v. Anthropic, an expert’s declaration was partially struck for an acknowledged “AI hallucination.”
These are not hypothetical risks. They are published opinions, and opposing counsel in your next case has read every one of them.
AI Is a Third Party, Not a Private Workspace
The deeper problem goes beyond hallucinated citations. When you paste confidential case material into a cloud-based LLM, you are transmitting it to a third party. The legal consequences of that act are now settled law.
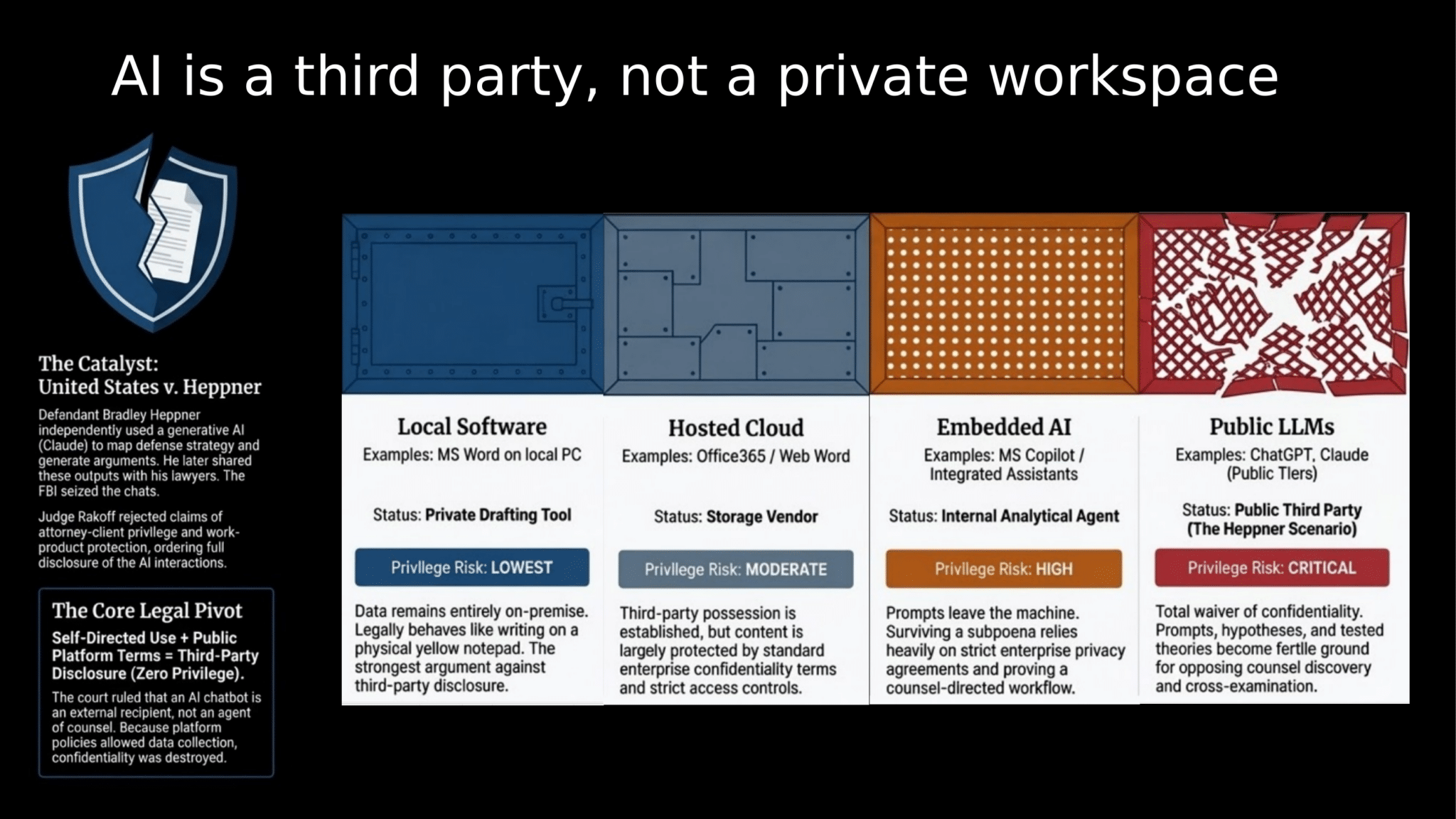
In United States v. Heppner, the court ruled that AI chat logs were fully discoverable — no attorney-client privilege, no work-product protection. The formula is straightforward: self-directed use + public platform terms = third-party disclosure with zero privilege. Every prompt you type, every strategy you explore, every draft you refine through a public LLM becomes fertile ground for opposing counsel’s discovery requests.

Cloud Providers Are Serious — but Fall Short
You might reasonably ask: “What about enterprise cloud AI? Surely AWS, Azure, and OpenAI’s business tiers solve this?” They try. These platforms invest heavily in security certifications, encryption, and contractual assurances.
But the protective orders governing your case documents don’t care about SOC 2 badges. A typical protective order in federal litigation enumerates exactly who may access confidential material — and none of the ten standard exceptions provide scope for uploading that material to a cloud LLM, no matter how many compliance certifications it holds. Meanwhile, cloud infrastructure breaches continue making headlines, and the gap between vendor promises and courtroom standards remains wide open.
Local Inference: A Solution Built for Litigation
Here’s where things get exciting — and where your technical background becomes a genuine competitive advantage. The same AI capabilities that make cloud LLMs so useful can now run entirely on hardware you control, in your own office, with no data ever leaving your local network.

This isn’t a theoretical exercise. Modern hardware — specifically Apple’s Mac Studio with the M3 Ultra chip and 512 GB of unified memory — can run state-of-the-art large language models locally with performance that would have been unthinkable two years ago. The key enabling technology is a class of models called Mixture-of-Experts (MoE) architectures, like Qwen3-235B-A22B. These models contain 235 billion parameters but activate only 22 billion for any given query, delivering GPT-4-class analytical capability while fitting comfortably in local memory.
How the Numbers Work
At Q4 quantization (a compression technique that preserves analytical quality while reducing memory footprint), Qwen3-235B requires roughly 130 GB of RAM. The M3 Ultra’s 800 GB/s memory bandwidth enables 16–24 tokens per second — fast enough for real-time question answering and overnight batch processing of large document sets. Add a 1 GB embedding model (nomic-embed-text) for semantic search, and you still have hundreds of gigabytes of headroom.
Compliance by Design: The Architecture
A well-designed local AI system isn’t just “an LLM on a laptop.” It’s a complete document-processing pipeline engineered for litigation workflows.

The workflow begins when you receive documents from retaining counsel. Files are downloaded into a dedicated per-case directory. PDFs are OCR-processed (using engines like Surya OCR that achieve 97%+ accuracy on technical documents with complex layouts, tables, and equations), images are optimized, and text is extracted. The processed content is then indexed into a per-case vector database — a semantic search index that lets you ask natural-language questions of your entire document corpus and get cited, sourced answers in seconds.
Every step runs on your local hardware. No cloud. No third-party transmission. Complete protective-order compliance by design, not by contract.
An Agent Architecture That Actually Works
The real power emerges when you pair local inference with an agent framework — software that turns a raw LLM into a persistent, capable research assistant. Platforms like OpenClaw provide the scaffolding: persistent memory across sessions, tool use (file system access, web search, code execution), scheduled background tasks, and the ability to spawn specialized sub-agents.

Consider a working system with four specialized agents. An orchestrator (Skuld) receives your questions via a messaging interface and intelligently routes them. Case-document queries go to Oracle, which runs Qwen3-235B locally and searches your per-case vector database to deliver answers with source citations. Code-generation tasks go to CodeWriter, running a separate local model (MiniMax-M2.5) for programming work. A quality-control agent reviews code output — and critically, this is the only agent that touches the cloud, and it handles only code, never case documents.
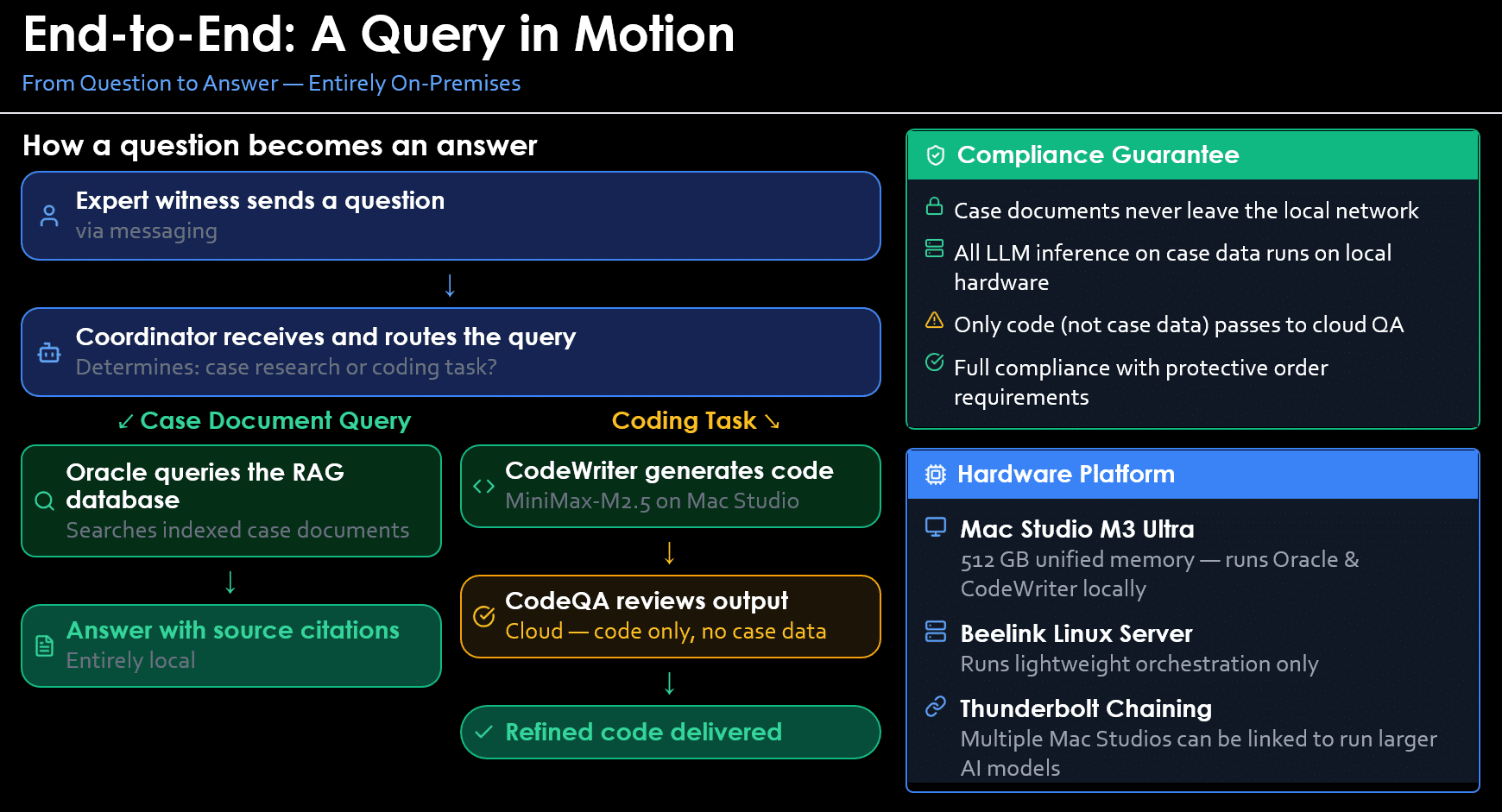
The result is an AI research assistant you can interact with as naturally as texting a colleague, that searches thousands of documents in seconds, that generates analyses and code on demand — and that maintains ironclad compliance with your protective order obligations.
Why This Matters for You
If you’re an expert witness with a technical background, you’re uniquely positioned to benefit from this technology. You already understand the underlying concepts — quantization is just data compression, vector databases are just high-dimensional indexing, MoE architectures are just conditional computation. The tools are mature, the hardware is commercially available, and the legal imperative is clear.
- Speed: Digest a 10 GB document dump in hours, not weeks
- Compliance: Protective-order materials never leave your network
- Credibility: No risk of AI hallucinations entering your work product unchecked
- Capability: GPT-4-class analysis running on a machine under your desk
- Independence: No subscription dependencies, no terms-of-service changes, no vendor lock-in
The expert witnesses who master this technology won’t just avoid the pitfalls that are ending careers — they’ll deliver faster, deeper, and more defensible analyses than their peers. In a field where credibility is everything, that advantage compounds with every case.
Ready to Explore Local AI for Your Practice?
Whether you’re evaluating hardware, selecting models, or designing a document-processing pipeline for your next case, I’m happy to discuss how local inference can fit your specific workflow and compliance requirements.
Consulting available on system architecture, model selection, and litigation-compliant AI deployment.